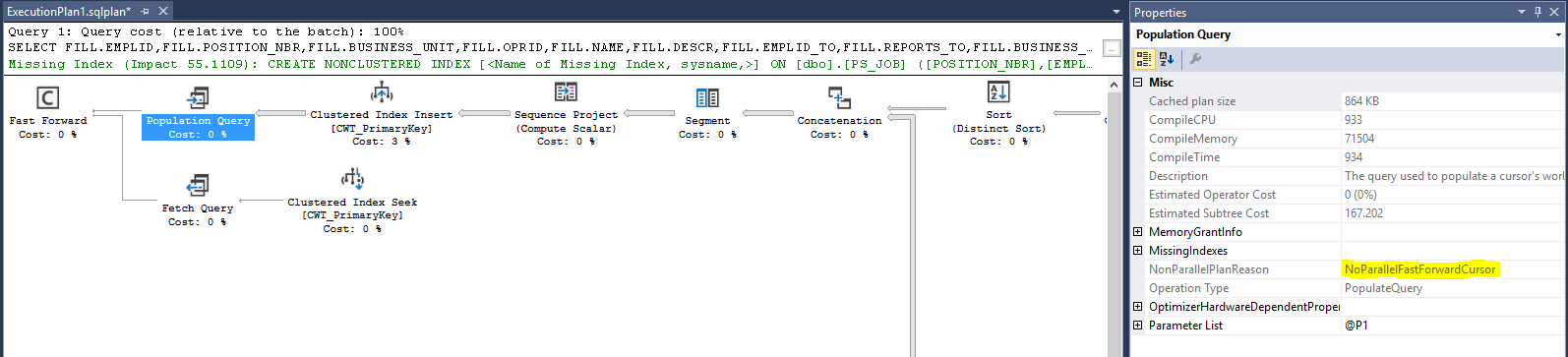
A common requirement is to generate a list of the dates between two dates e.g. on a source row we have a FROM and TO date but we need to expand that into a row for each date. One way to do that on SQL Server is via a CTE:
---
--- A generated list of dates from 01-01-2013 until 25-01-2054
--- This would be a useful utility view/table in any PS system
--- Table is preferred - CLUSTERED INDEX ON PROCESS_DT provides
--- Important statistics on distribution AND allows for a CLUSTERED INDEX SEEK
--- in execution plan.
---
WITH [PROCESS_DATES] AS (
SELECT TOP 15000 CAST(DATEADD(DAY,ROW_NUMBER() OVER ( ORDER BY RECNAME),CONVERT(DATE, '2012-12-31')) AS DATE) AS PROCESS_DT,
DATEPART(weekday,DATEADD(DAY,ROW_NUMBER() OVER ( ORDER BY RECNAME),CONVERT(DATE, '2012-12-31'))) AS PROCESS_DT_WEEKDAY
FROM PSRECFIELDDB --- ANY TABLE WITH A NUMBER OF ROWS >= THE TOP VALUE ABOVE WILL DO
) |
---
--- A generated list of dates from 01-01-2013 until 25-01-2054
--- This would be a useful utility view/table in any PS system
--- Table is preferred - CLUSTERED INDEX ON PROCESS_DT provides
--- Important statistics on distribution AND allows for a CLUSTERED INDEX SEEK
--- in execution plan.
---
WITH [PROCESS_DATES] as (
SELECT TOP 15000 CAST(DATEADD(DAY,ROW_NUMBER() OVER ( ORDER BY RECNAME),CONVERT(DATE, '2012-12-31')) AS DATE) AS PROCESS_DT,
DATEPART(weekday,DATEADD(DAY,ROW_NUMBER() OVER ( ORDER BY RECNAME),CONVERT(DATE, '2012-12-31'))) AS PROCESS_DT_WEEKDAY
FROM PSRECFIELDDB --- ANY TABLE WITH A NUMBER OF ROWS >= THE TOP VALUE ABOVE WILL DO
)
That works fine, but as the comments above indicate, if you are going to do this it is better to generate the list of values into an table, Apart from anything else, why incur the CPU time recalculating this list every time it is accessed – better as a one-off table populate. Note the use of a table known to have more that 15000 rows – this could be any table – even sys.all_objects provided it has enough rows. But if you are generating rows as a one-off you could cartesian (star join) tables to themselves to get enough rows. The 15000 is arbitrary – you could go further ahead.