PeopleTools was designed to be database agnostic. In the past, the database support included databases such as Gupta SQLBase, Allbase, Informix and Sybase. The ability to support multiple platforms and add others relatively easily was a consequence of some excellent initial design decisions. Sadly, database platform support has dwindled to Oracle, SQL Server and DB2 in more recent releases of PeopleTools.
However, supporting multiple databases in this way meant that many database specific features were not taken advantage of. Since the Oracle takeover of Peopleoft, there have been some moves to add some Oracle database specific feature support e.g. GTT, but almost nothing on the other databases.
Although there is support in PeopleTools for database specific SQL and indeed database specific indexes on tables, some of the assumptions about the database do not fit SQL Server at all well.
Architectural Decisions
On SQL Server (and Sybase), the accepted practice is to create a table with a clustered index and other Non-Clustered indexes. This is in contrast to most other PeopleTools supported databases and most notably Oracle, where the choice is typically a heap with a set of non-clustered indexes. Clustered tables (indexes) are, of course, an option on Oracle too but they are not typically used and are not used on Oracle by PeopleTools. This architectural difference makes any meaningful comparison of performance of PeopleSoft on SQL Server versus Oracle problematic. It also leads to some interesting performance tuning challenges on SQL Server as non-clustered indexes are very much treated as second-class citizens compared to the clustered index unless the index is covering e.g. the index includes all columns needed by the query either in the index or via leaf-node inclusion using INCLUDE on non-clustered index creation.
PeopleTools Indexing
PeopleTools automatically adds a (typically unique) index for the “key” fields on a table – on SQL Server this is generally (but not always – see my previous article on PSTREENODE) flagged as a Clustered Index:

PeopleTools also automatically adds indexes to support fields flagged as “alternate search” (indexes 0 to 9) e.g.
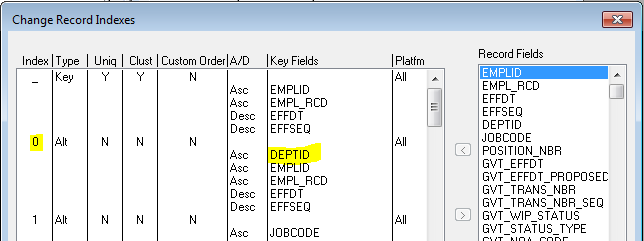
These indexes lead with the field flagged as the alternate search key and include all of the “key” fields in the index itself. This approach assumes the underlying table is a heap with non-clustered indexes. On SQL server, the inclusion of the “key” fields from the clustered index is not really necessary (the clustered index keys are included anyway if there is a clustered index). However, should the clustered index be changed to non-clustered then these fields could offer some performance benefit to queries where they are effectively covering indexes i.e. the query requires only the fields available from the non-clustered index.
The performance challenge with SQL server is that the clustered index will nearly always be favoured by the optimizer as it gives immediate access to all fields on the row. The dynamic nature of much of the PeopleTools generated SQL also tends to push the optimizer towards the clustered index as the developer often has little appreciation of the SQL being generated or things like prompts and auto-select population of scroll areas.
Often, the biggest downside of this favouring of the clustered index is that the width of the rows means that scanning the clustered index (a table scan in reality) will require reading many pages (blocks) of data – and hence many logical I/O’s. Other non-clustered indexes may be used by the optimizer but only if the cost of doing an index lookup plus a keyed lookup is considered cheaper – and that is very much dependent on the optimizer’s ability to determine cardinality from statistics. In general, the larger the number of estimated rows, the less likely it is that the optimizer will use a non-clustered non-covering index.
With modern storage hardware and the large amounts of memory available to databases, there has been tendency for people to ignore the cost of logical I/O’s – they’re really fast right? Except it just isn’t true when you start talking about 100’s of thousands or even 100’s of millions of logical I/O’s. And those sort of numbers are not at all unusual on PeopleSoft applications.
Fortunately, the PeopleTools developers did provide a way for DBAs and PS admins to improve performance by allowing them to extend the index creation templates (DDL defaults etc) to add things like INCLUDE and WHERE support to indexes on SQL Server (see PeopleSoft – INCLUDE and WHERE (filtering) on SQL Server Indexes for details on how to do this within PeopleTools).
For high volume IB workloads on SQL server, adding suitable filtered indexes on the publication message header and subscription contract that filter on “status” “New” (e.g. PUBSTATUS = 1 / SUBCONSTATUS=1) with appropriate INCLUDEd columns can have a dramatic impact on the performance of IB processing, especially if you are a site that does not archive/delete historic IB transactions aggressively.