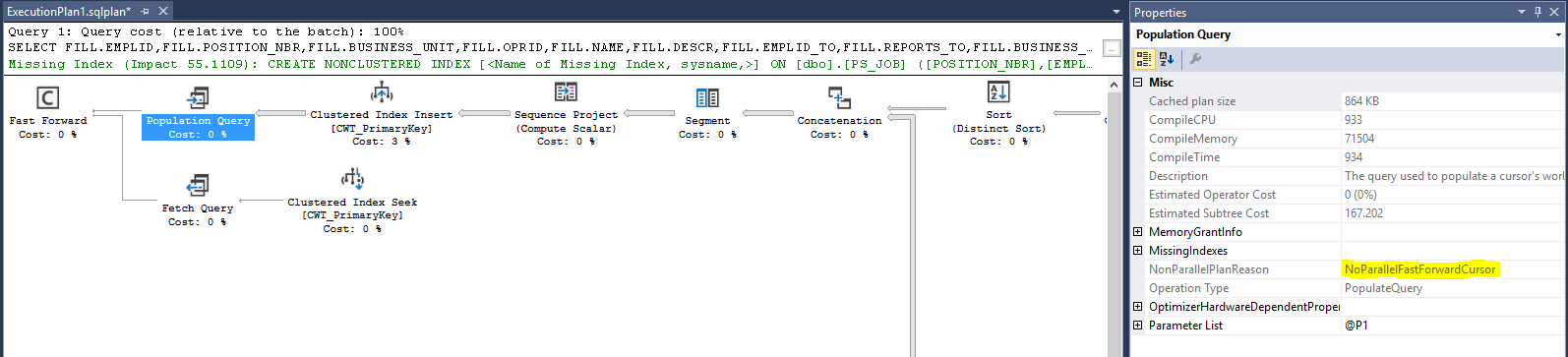
Way back in 1998 I was implementing PeopleSoft Financials 7.5 for a UK Charity. SQR and Application Engine (the COBOL version back then) were the only options available in the PeopleSoft toolset for updating the database. Other than straight SQL updates in SQLPlus of course!
Whilst SQR was an OK tool, I always felt it lacked so many capabilities. In fact, at that point it could not even read a CSV file – I had to code a user DLL in C to achieve even that. All very frustrating.
Having rescued various projects using perl scripts prior to this, I decided I would add perl as an available language to process scheduler. Taking the SQR include files for the process scheduler API as an example, I emulated the same approach with perl. It worked brilliantly and allowed me to add some sophisticated features to PeopleSoft including:
- SQL and query output to CSV and XLS formats (remember this was prior to the PeopleSoft Internet Architecture) through the SpreadSheet::WriteExcel, and DBD::CSV CPAN modules
- User defined SFTP/FTP/SCP file transfers to and from third-party systems
- Bank Statement loads by encapsulating mainframe remote access software into process scheduler jobs
- Exchange rate loading via Website “screen scraping”
- Spreadsheet Aged Debt reporting
- Fuzzy duplicate customer identification/matching
- Automatic customer identification in Accounts Receivable
Here’s the start of one such perl script from 2004:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| #!/usr/bin/perl
#
# This is a perl routine to find possible matches for originator's
# sort code and bank account by looking to find possible customers.
#
# (1) Fetch the list of bank statement entries.
# (2) Try to find customer like this.
#
# Author: XXX
# Date : 29th January 2004.
#
# Amendment History
# -----------------
# 29-JAN-2004 XXX First version
#
#$debug = 1;
use lib 'h:\perl';
use Strict;
use Spreadsheet::WriteExcel::Big;
use String::Approx qw(amatch);
require 'prcsapi.pl';
use Date::Calc qw (Delta_Days);
$row = 0;
#
# Connect to database using parameters resolved from command line
#
$dbh = DBI->connect( "dbi:$dbtype:$dbname", "$accessid", "$accesspswd" ) or die $dbh->errstr; |
#!/usr/bin/perl
#
# This is a perl routine to find possible matches for originator's
# sort code and bank account by looking to find possible customers.
#
# (1) Fetch the list of bank statement entries.
# (2) Try to find customer like this.
#
# Author: XXX
# Date : 29th January 2004.
#
# Amendment History
# -----------------
# 29-JAN-2004 XXX First version
#
#$debug = 1;
use lib 'h:\perl';
use Strict;
use Spreadsheet::WriteExcel::Big;
use String::Approx qw(amatch);
require 'prcsapi.pl';
use Date::Calc qw (Delta_Days);
$row = 0;
#
# Connect to database using parameters resolved from command line
#
$dbh = DBI->connect( "dbi:$dbtype:$dbname", "$accessid", "$accesspswd" ) or die $dbh->errstr;
The require of prcsapi.pl brings in all the necessary sub-modules needed for the process scheduler API. Updating the process scheduler status is then simply a call to the appropriate API function:
1
| Update_Process_Status($prcs_run_status_processing,'Processing has started.'); |
Update_Process_Status($prcs_run_status_processing,'Processing has started.');
More recently, I have taken a similar approach but for ruby …. more on that later.
Enjoy.