During a recent discussion with another PS Admin running on SQL Server it became apparent that his efforts to improve application SQL performance through adding more CPUs (with the associated license costs) were based on a fundamentally wrong assumption:
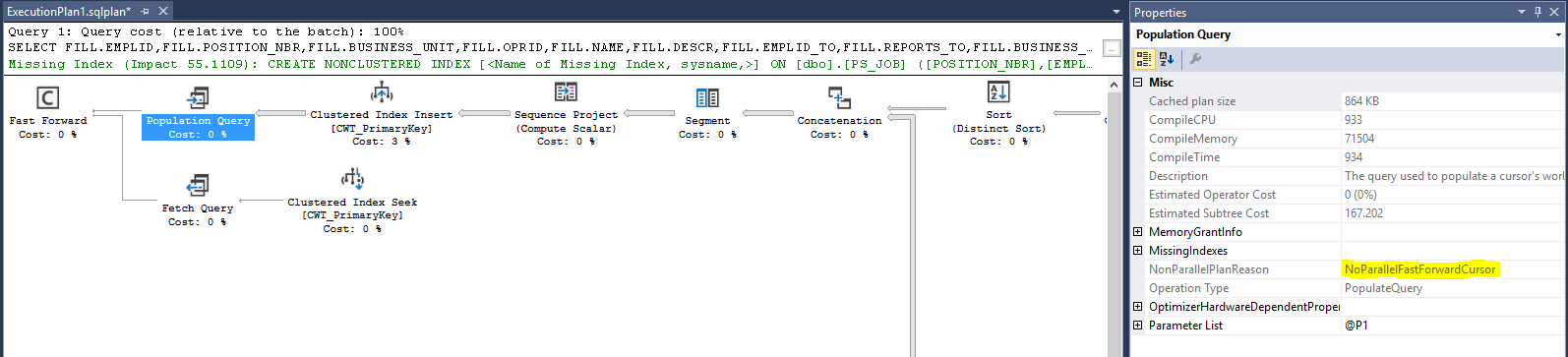
PeopleTools/Application SQL will go parallel if needed.
This is simply not true. In fact, most SELECT SQL can never go parallel under PeopleTools on SQL server due to the fact that they are run through cursors and PeopleTools requests a cursor type of FAST_FORWARD. FAST_FORWARD cursors result in an execution plan with a NonParallelReason value of NoParallelFastForwardCursor.